Buddy System — 커널 메모리 할당자의 핵심 아이디어
Linux 커널의 물리 메모리 관리 방식인 Buddy System을 정리한 글입니다. 단편화 문제를 해결하는 원리부터 그 위에 쌓인 Slab, TCMalloc, Jemalloc까지 계층적으로 살펴보았습니다.
'컴퓨터 밑바닥의 비밀'의 'Ch3. 저수준 계층? 메모리라는 사물함에서부터 시작해보자'를 읽으며 OS 수업에서 배웠던 메모리 할당 개념을 다시 공부해보는 기회가 되었다. malloc이 실제로 어떻게 동작하는지, 그 아래 커널 레벨에서 무슨 일이 벌어지는지를 따라가보았다.
Buddy System이란
가변 분할의 외부 단편화를 줄이기 위해 2의 거듭제곱 분할 규칙을 도입한 동적 메모리 할당 기법
할당했던 메모리를 해제하고 나면 여유 메모리는 여기저기 흩어져 있을 가능성이 높다. 남은 여유 메모리의 합은 충분한데 요청 크기를 하나의 연속된 조각으로 만족할 수 없는 상황을 메모리 단편화(Fragmentation) 라 부른다.
Buddy System은 이 문제를 해결하기 위해 등장했으며, Linux 커널의 물리 메모리 관리자로 사용되고 있다.
메모리 단편화
단편화는 외부 단편화/내부 단편화 두 종류로 나눌 수 있고 서로 trade-off 관계에 있다. 내부 단편화를 줄이면 외부 단편화가 늘고, 외부 단편화를 줄이면 내부 단편화가 는다. Buddy System은 외부 단편화 최소화를 택하고 내부 단편화는 감수한다.
외부 단편화
앞서 언급한 문제는 외부 단편화의 사례로 볼 수 있다
전체 여유 메모리: 100KB (충분함)
실제 상태:
[사용중 30KB] [비어있음 10KB] [사용중 20KB] [비어있음 15KB] [사용중 10KB] [비어있음 15KB]
→ 50KB 연속 메모리 요청 → 실패
여유 메모리가 흩어져 있어 연속된 50KB를 만들 수 없음
내부 단편화
할당된 블록 안에서 낭비되는 공간이다.
36KB 요청 → 64KB 블록 할당 (28KB 낭비)
핵심 아이디어 — 2의 거듭제곱 분할
블록 크기를 2의 거듭제곱으로 고정해서 내부 단편화는 감수하되 외부 단편화를 획기적으로 줄인다. 단, 완전한 제거는 어렵다.
 *출처 -
*출처 - - 모든 블록의 크기는 2의 거듭제곱 (2⁰, 2¹, 2², ... 2ⁿ)
- 블록을 반으로 나누면 둘은 서로의 "buddy" — 둘 다 비어있으면 다시 합칠 수 있다
예: 1024KB → 512 + 512 (buddy)
→ 256 + 256 (buddy) + 512
Linux Order 체계
Linux 커널은 블록 크기를 order로 표현한다. Order k = 4KB × 2^k.
| Order | 블록 크기 | 페이지 수 |
|---|---|---|
| 0 | 4KB | 1 |
| 1 | 8KB | 2 |
| 2 | 16KB | 4 |
| 3 | 32KB | 8 |
| 4 | 64KB | 16 |
| 5 | 128KB | 32 |
| ... | ... | ... |
| 10 | 4MB | 1024 |
order는 총 11단계(x86 Linux 기준)로 구성되며, 각 order마다 여유 블록 리스트를 따로 관리한다.
/* 할당 경로 (단순화) */
Order-0 요청 → per-CPU pageset 먼저 확인 (lock 없음)
↓ 비어있으면
그 외 or PCP miss → Buddy free_area (spinlock)
 *출처 - A Quick Dive Into The Linux Kernel Page Allocator
*출처 - A Quick Dive Into The Linux Kernel Page Allocator/proc/buddyinfo로 상태 확인
cat /proc/buddyinfo
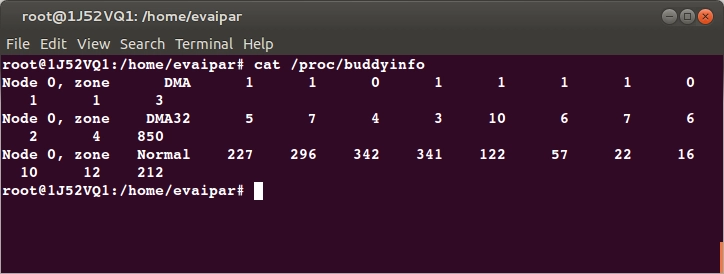
*출처 - The power of PROC file system in Linux
Buddy System이 관리하는 물리 메모리는 하드웨어 제약에 따라 세 구역으로 나뉜다.
| Zone | 범위 | 존재 이유 |
|---|---|---|
| DMA | 하위 16MB | 구형 ISA 장치가 16MB 이상 DMA 불가 — 하위 호환성 |
| DMA32 | 하위 4GB | 일부 하드웨어가 32bit 주소 범위 내에서만 DMA 가능 |
| Normal | 4GB 이상 | 일반 커널/사용자 메모리 |
프로그래머가 malloc으로 요청하면 가상 주소를 받지만, 실제 물리 페이지가 어느 Zone에서 공급되는지는 하드웨어 제약과 GFP 플래그에 따라 결정된다.
정렬 보장
블록을 항상 반으로 쪼개기 때문에 같은 order의 블록들은 그 크기만큼 정렬된 주소에 위치한다. Order 4 (64KB) 블록의 시작 주소는 항상 64KB의 배수다. 이 정렬 덕분에 물리적으로 연속된 메모리가 보장된다.
즉, 수학적 구조가 알고리즘의 성능을 결정한 것이다.
장단점
| 장점 | 단점 |
|---|---|
| buddy 주소 조회가 XOR 연산으로 O(1) 물리 페이지 관리에 적합 | 내부 단편화가 크다 (최대 거의 2배 낭비) 작은 객체 할당에 비효율적 락 경합 발생 가능 |
메모리 할당 — 블록을 쪼개는 과정
예시: 36KB 요청
STEP 1. 36KB를 만족하는 최소 order 찾기
36KB → 4KB × 2⁴ = 64KB (order 4)
STEP 2. Order 4 리스트 확인 → 비어있음
STEP 3. 상위 order(5, 128KB) 리스트 확인 → 있음
STEP 4. 128KB 블록을 반으로 분할
→ 64KB (할당, order 4) + 64KB (buddy, order 4 리스트에 추가)
시간 복잡도: O(log N)
order가 최대 11단계이므로 탐색 횟수의 상한이 고정되어 있다.
메모리 해제 — Buddy를 찾아서 병합하는 과정
Buddy 주소 계산
buddy_address = block_address XOR block_size
예시: block_address = 0x0000, block_size = 64KB = 0x10000
buddy_address = 0x0000 XOR 0x10000 = 0x10000
2의 거듭제곱 정렬 덕분에 XOR 연산 하나로 buddy 주소를 계산할 수 있다. 블록이 크기에 맞게 정렬되어 있으면 XOR 연산이 정확히 짝이 되는 주소를 가리킨다.
Linux 커널 내부 구현은 byte address 대신 PFN(page frame number)으로 계산한다.
buddy_pfn = page_pfn ^ (1UL << order)
두 표현은 수학적으로 동치다.
buddy 주소 계산 이후:
- buddy가 사용 중 → 현재 order 리스트에 추가
- buddy가 여유 상태 → 병합 후 상위 order 리스트에 추가
상위 buddy 역시 여유 상태라면 재귀적으로 병합을 수행해 상위 order로 타고 올라가는 구조이다.
시간 복잡도
- buddy 주소 조회: XOR 연산 O(1)
- 재귀 병합 전체: 최악 O(MAX_ORDER) = O(11). 상한이 고정되어 있어 실질적으로 빠르다
즉시 병합 (Eager Merge)
다음 할당 시점까지 미루는 lazy 방식이 아닌, buddy 조회 비용이 O(1)로 충분히 가능하기 때문에 해제 즉시 병합하여 큰 연속 블록을 빠르게 복원할 수 있다.
계층적 발전 흐름
Buddy System 이후에 각 계층이 등장한 이유를 순서대로 살펴보자
① Slab Allocator
Buddy System은 페이지(4KB) 단위 이상의 할당에 적합하다. 그보다 작은 커널 오브젝트(task_struct, inode 등)는 할당할 때마다 초기화 비용이 크다는 문제가 있었다.
Slab Allocator는 페이지를 잘라서 특정 타입의 객체를 담는 slab 단위로 관리하며, Buddy 위에서 free list를 캐싱한다. (객체 단위 캐싱 개념)
물리 메모리 계층:
Buddy System → 페이지 단위 (4KB~) 관리
↓ 페이지 공급
Slab Allocator → 작은 커널 오브젝트 관리 (캐시 기반)
↓ 오브젝트 공급
커널 코드 → task_struct, inode 등 할당
현재 Linux 기본: SLUB
Linux 2.6.23(2007)부터 SLUB이 기본 할당자로 채택됐다. Slab의 복잡한 공유 캐시 구조를 단순화한 버전으로 디버깅 편의성과 NUMA 효율성을 개선했다. 개념 수준의 계층 위치는 동일하다.
② TCMalloc (Google)
멀티코어 환경에서 malloc을 스레드 A와 B가 동시에 호출한다고 가정해보자. 같은 free list에 락 경합이 발생할 것이고, 멀티코어임에도 순차 실행되는 병목이 발생할 수 있다.
Thread-Caching Malloc — 각 스레드가 자기만의 small object cache를 가지는 구조
③ Jemalloc (Meta)
외부 단편화 최소화 + 멀티코어 확장성. Arena라는 독립적인 힙을 스레드에 매핑하는 구조
정리 — 발전 흐름
| 단계 | 해결 대상 | 핵심 아이디어 | 한계 |
|---|---|---|---|
| Buddy | 물리 페이지 단편화 | 2^k 분할/병합, XOR buddy 계산 | 내부 단편화 |
| Slab (SLUB) | 커널 소형 객체 | 객체 캐싱, 초기화 비용 절감 | 유저 영역 다양성 부족 |
| TCMalloc | 멀티스레드 락 경합 | Thread-local cache | 메모리 사용량 증가 가능 |
| Jemalloc | 대규모 서버 다양성 | Arena + size class | 복잡성 증가 |